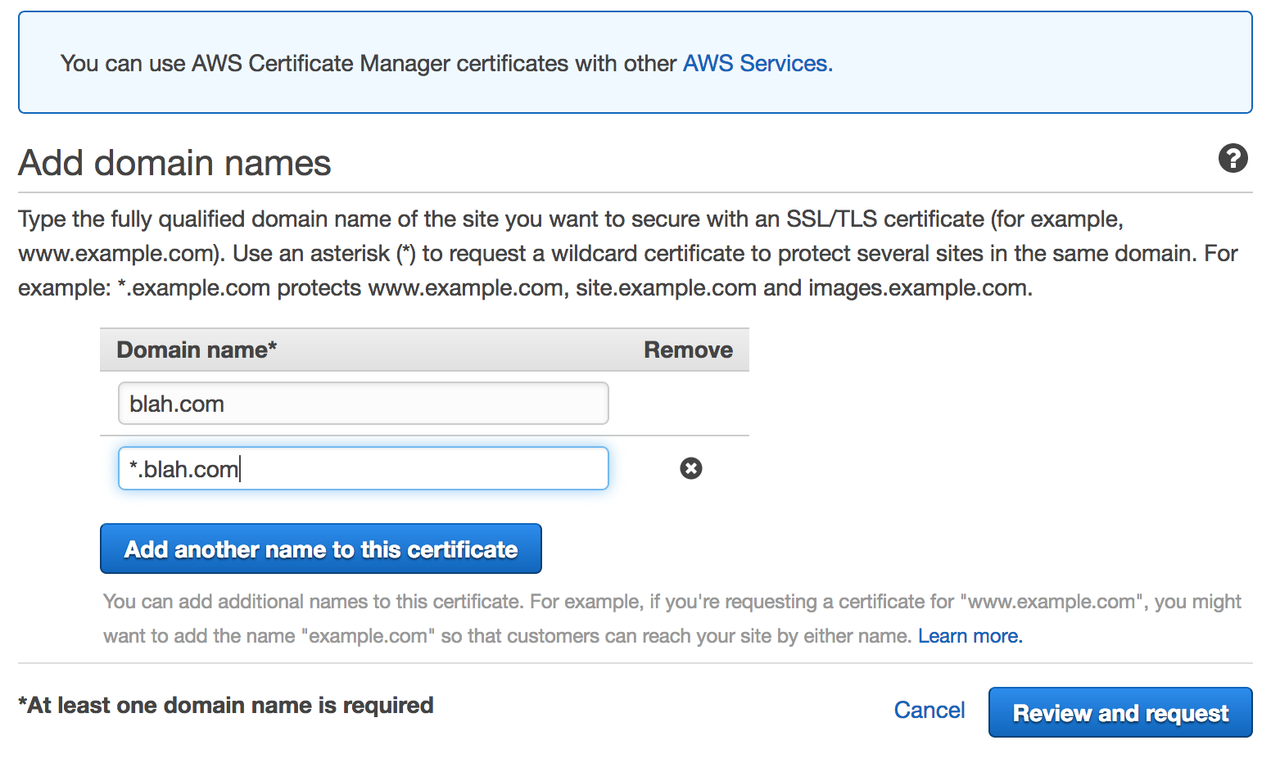
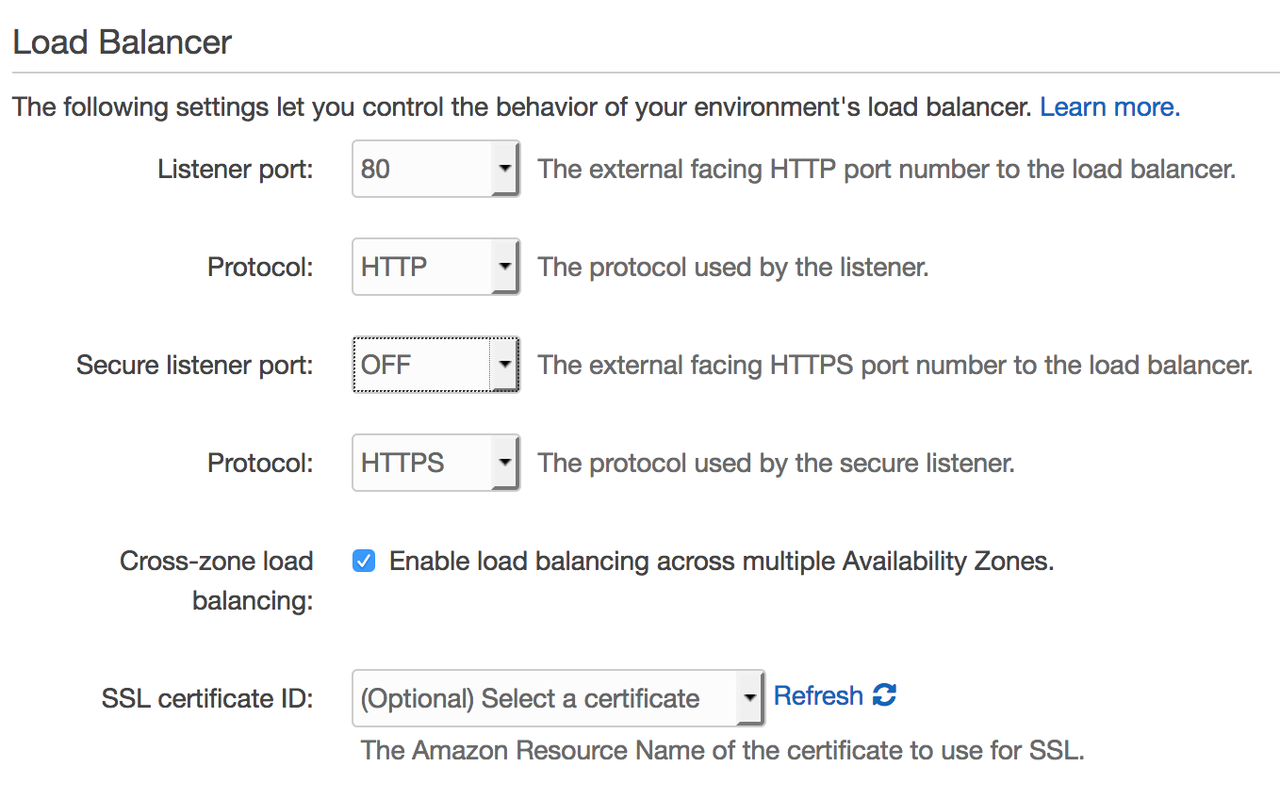
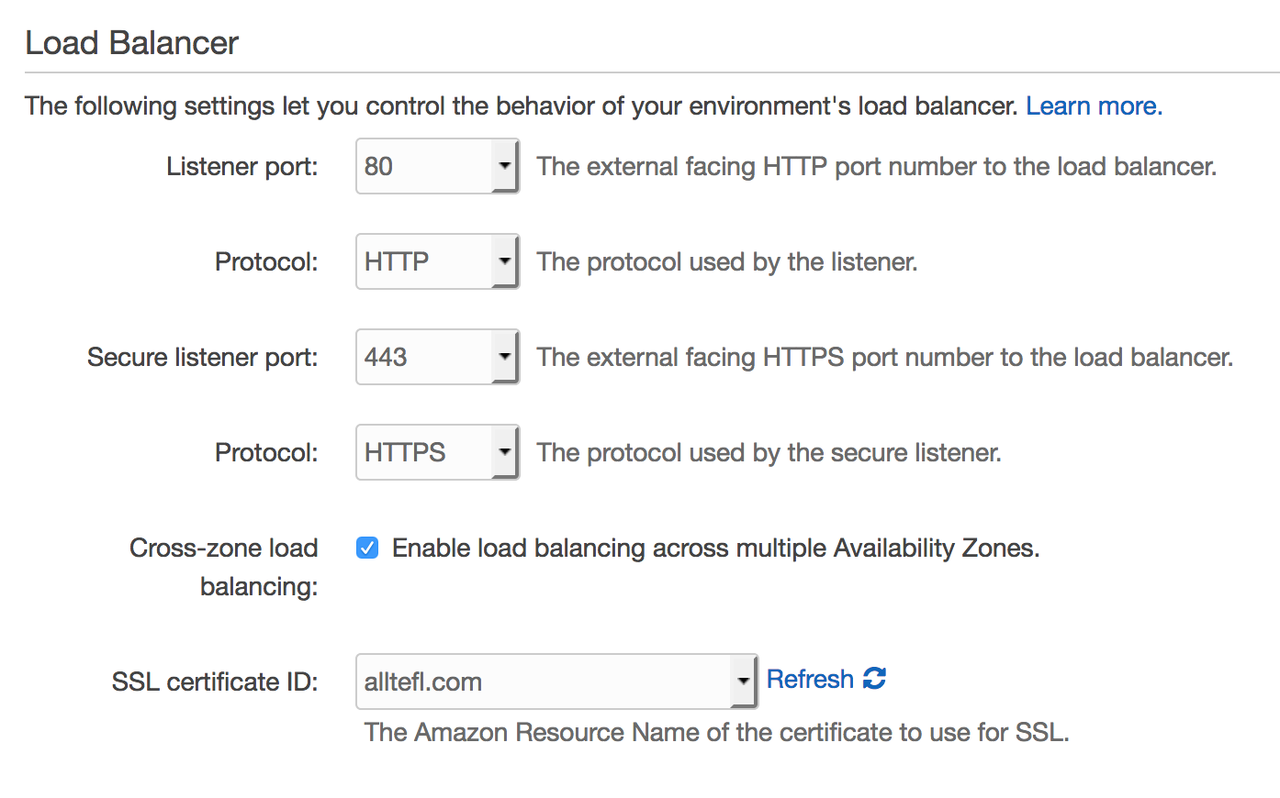
Over the past months I've been working in my spare time on a Django based website, allTEFL, a sort of Glassdoor site for TEFL teachers. This was the project that first made me want to learn to program, and it is hugely exciting to see it come to life.
This is the first in a series of posts in which I'll describe how I designed and organized the site, then talk about some of the fun coding challenges I came across as I worked on it.
First we'll walk through some simple user stories, then talk about how use case scenarios affected how I created my models.
User Stories
At first, I figured that there would basically be three things that would happen:
- A
Teacher creates an account so she can review a school (school_review) or a recruiter (recruiter_review).
- A
Teacher adds a school_review to the database. This is publicly viewable as an anonymous post on the School's page.
- Specific data from the
school_review (school name, dates of employment) is visible in the Teacher's resume_view.
Putting the Parts Together
Creating a Teacher model was easy; use Django's auth.User model. The School model has proven to be much more interesting.
The School
A Teacher has a one-to-many relationship with Schools that she's taught at and reviewed.
First, a complication: there is no complete list of all the English schools or TEFL recruiters in China. Thus, (2) above has a problem: the Teacher's School may not exist in the database. So let's revise my user stories:
- A
Teacher adds a school_review for a School in the database.
- If the
School is not in the database already, the Teacher adds it before reviewing it.
Cool. But as it turns out, doing this is a bit harder than it seemed at first glance.
Letting a user add Schools to the database is problematic because we don't want data to be fragmented. (One teacher might enter Beijing High School, but another teacher from the same school might look for BHS and then create a new instance of the School model.) So it's important to make finding your school's name as streamlined and precise as possible, reducing peoples' temptation to not look and just add a new school.
We could just add schools by name, but this is problematic because Schools may well share names. For example, there are a number of chain schools, similar to test prep behemoths Kaplan or Princeton Review in the US. We want to make sure Wall Street English in Wudaokou, Beijing is distinguishable from WSE in Zhongguancun, Beijing. Also, users will doubtless want to look up schools by location So, just having a list of schools organized by name is not an appropriate way to organize the db.
Chained Selects in Django
So, how about a chained lookup in our form. A chained lookup means finding all Y that belong to X. This will allow us to select schools (and enter them into the database) based on location. The user can select a Province, which brings up a list of all its City. After selecting the City, you can either (a) select your School or (b) add_school to the database if necessary.
Country -> Province List -> City List -> Schools
e.g.
China -> Jilin -> Changchun -> Sino-American Denver Foreign Language School
But to do this, I need a list of all the provinces (and their constituent cities) in a given country. That sounds like quite a bit of work to do by hand…so surely someone's automated it, right?
There are two Django packages that can be combined to (a) populate tables with country, province/state, and city data, and (b) make it easy to build geographic chained selections: django-cities-light and django-smart-selects. Below I will show you how to use the two together to create your own forms in Django that automatically whittle down information from the database to
For my use case it's been necessary to make custom models so I can have views for city, region, and city. Because of this, I need to use the abstract models included in cities_light.
#models.py
from cities_light.abstract_models import AbstractCountry, AbstractRegion, AbstractCity
These are our necessary imports. First, we are using the generic models from django-cities-light: Country, Region, and City.
IMPORTANT There is a known bug in django-cities-light's abstract models that requires you to declare your models in the same order that you imported the Abstract models.
from cities_light.abstract_models import AbstractCountry, AbstractRegion, AbstractCity
from cities_light.receivers import connect_default_signals
#models.py
class Country(AbstractCountry):
pass
connect_default_signals(Country)
class Region(AbstractRegion):
pass
connect_default_signals(Region)
class City(AbstractCity):
pass
connect_default_signals(City)
We need to register our custom models in the site's settings.py:
# settings.py
CITIES_LIGHT_TRANSLATION_LANGUAGES = ['zh', 'en'] # I want to include both Chinese & English names
CITIES_LIGHT_INCLUDE_COUNTRIES = ['CN'] # Download geographic information for China.
CITIES_LIGHT_APP_NAME = 'app_name' # Let the app know that I have custom models, defined in this app.
From the terminal we now need to run ./manage.py cities_light to populate the tables. Three tables will be created: country, region, and city. The tables have a bunch of columns in them. The most important are:
country
| id |
name_ascii |
slug |
| 1 |
China |
china |
region
| Header One |
Header Two |
| Item One |
Item Two |
| id |
name_ascii |
slug |
display_name |
country_id |
| 2 |
Qinghai |
qinghai |
Qinghai, China |
Foreign Key |
Worth noting that this model has a foreign key, country_id, that associates with a country.
city
| id |
name_ascii |
slug |
display_name |
country_id |
region_id |
| 1 |
Rikaze |
rikaze |
Rikaze, Tibet Autonomous Region, China |
ForeignKey(country_id) |
ForeignKey(region_id) |
Two foreign keys here - country_id and region_id.
The tables include multiple versions of the location's name. I've found name_ascii and display_name to be the two most useful. THe latter includes province and country.
Linking to City/Province/Country views
Our existing models are nice, but I want to be able to link to views for each of these models. This means writing a get_absolute_url function for them in my models, adding URL patterns to urls.py, and adding views for each.
# models.py
class Country(AbstractCountry):
def get_absolute_url(self):
return reverse('country_school_list',
kwargs={'country_slug': self.slug})
connect_default_signals(Country)
class Region(AbstractRegion):
def get_absolute_url(self):
return reverse('province_school_list',
kwargs={'country_slug': self.country.slug,
'province_slug': self.slug})
connect_default_signals(Region)
class City(AbstractCity):
def get_absolute_url(self):
return reverse('city_school_list',
kwargs={'country_slug': self.country.slug,
'province_slug': self.region.slug,
'city_slug': self.slug})
connect_default_signals(City)
# urls.py
url(r'^schools/(?P<country_slug>[\w-]+)/$',
CountrySchoolList.as_view(),
name='country_school_list'),
url(r'^schools/(?P<country_slug>[\w-]+)/(?P<province_slug>[\w-]+)/$',
ProvinceSchoolList.as_view(),
name='province_school_list'),
url(r'^schools/(?P<country_slug>[\w-]+)/(?P<province_slug>[\w-]+)/(?P<city_slug>[\w-]+)/$',
CitySchoolList.as_view(),
name='city_school_list'),
# views.py
from django.views.generic import ListView, DetailView, CreateView
from .models import School, Country, Region, City
class CountrySchoolList(ListView):
model = School
template_name = "school_reviews/school_list.html"
ordering = ('school_province', 'school_city', 'school_name')
def get_queryset(self, **kwargs):
self.country = get_object_or_404(Country, slug=self.kwargs['country_slug'])
return School.objects.filter(school_country=self.country)
def get_context_data(self, **kwargs):
context = super(CountrySchoolList, self).get_context_data(**kwargs)
context['section'] = 'country'
return context
class ProvinceSchoolList(ListView):
model = School
template_name = "school_reviews/school_list.html"
ordering = ('school_city', 'school_name')
def get_queryset(self, **kwargs):
self.country = get_object_or_404(Country, slug=self.kwargs['country_slug'])
self.province = get_object_or_404(Region, slug=self.kwargs['province_slug'])
return School.objects.filter(school_country=self.country,
school_province=self.province)
def get_context_data(self, **kwargs):
context = super(ProvinceSchoolList, self).get_context_data(**kwargs)
context['section'] = 'province'
return context
class CitySchoolList(ListView):
model = School
template_name = "school_reviews/school_list.html"
ordering = ('school_name')
def places(self, **kwargs):
country = get_object_or_404(Country, slug=self.kwargs['country_slug'])
province = get_object_or_404(Region, slug=self.kwargs['province_slug'])
city = get_object_or_404(City, slug=self.kwargs['city_slug'])
return country, province, city
def get_queryset(self, **kwargs):
self.country = get_object_or_404(Country, slug=self.kwargs['country_slug'])
self.province = get_object_or_404(Region, slug=self.kwargs['province_slug'])
self.city = get_object_or_404(City, slug=self.kwargs['city_slug'])
return School.objects.filter(school_country=self.country,
school_province=self.province,
school_city=self.city)
def get_context_data(self, **kwargs):
context = super(CitySchoolList, self).get_context_data(**kwargs)
context['section'] = 'city'
context['country'] = get_object_or_404(Country, slug=self.kwargs['country_slug'])
return context
Smart Selects
The last thing we need to do is write our models incorporating the ChainedForeignKey that django-smart-selects provides. Keep in mind that the chained_field is the name in your model, while the chained_model_field is the name in your database. My names aren't the same since I used django-cities-light to populate the db.
# models.py
class School(models.Model):
school_name = models.CharField(blank=False, max_length=200, unique=True)
slug = models.SlugField(unique=True)
school_country = models.ForeignKey(Country)
school_province = ChainedForeignKey(
Region,
chained_field="school_country",
chained_model_field="country",
help_text="The school's province."
)
school_city = ChainedForeignKey(
City,
chained_field='school_province',
chained_model_field='region',
show_all=False,
help_text="The school's city."
)
def save(self, *args, **kwargs):
self.slug = slugify(self.school_name)
super(School, self).save(*args, **kwargs)
def __str__(self):
return self.school_name
class Meta:
ordering = ('school_country', 'school_province', 'school_city', 'school_name')
And there you have it. A Django model that relies upon chained selections of geographic data that have been auto-populated to your database.